深入理解 ebpf loader
总结 ebpf 程序的生命周期 workflow,阅读 bpf load 的源码,通过注释笔记的方式理解 bpf loader 的原理。

ebpf workflow
首先试着从 ebpf 程序生命周期的角度总结整个工作流:
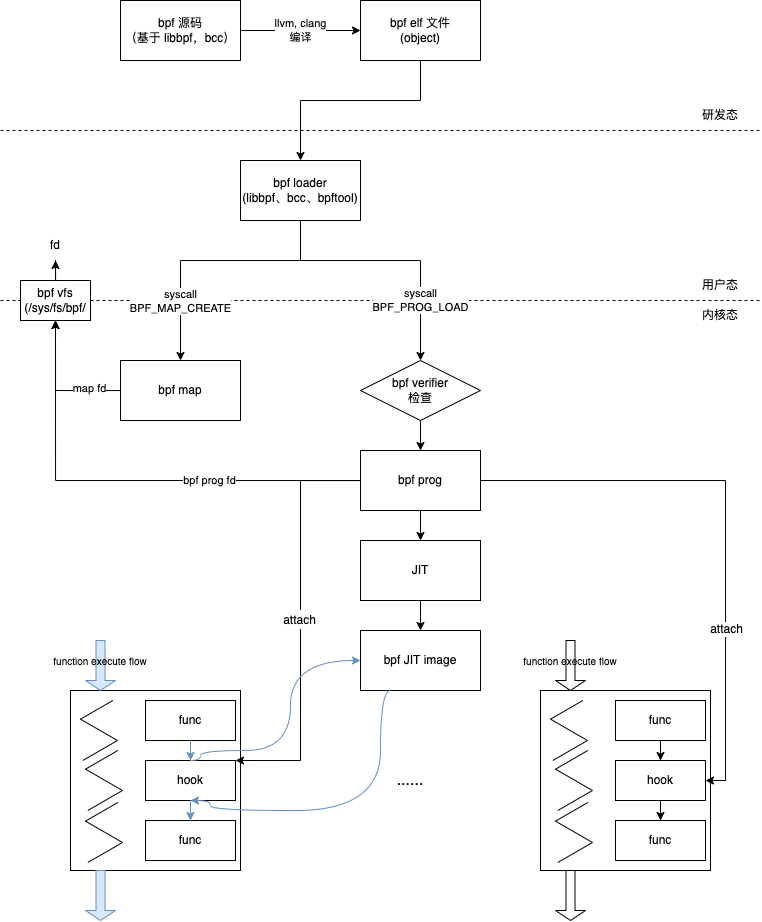
ebpf loader 分析
BPF_PROG_LOAD 系统调用命令负责加载一段BPF程序到内核当中:
- 拷贝程序到内核;
- 校验它的安全性;
- 如果可能对它进行JIT编译;
- 然后分配一个文件句柄fd给它;
完成这一切后,后续再把这段BPF程序挂载到需要运行的钩子上面。
ebpf 程序加载的代码主要在 ebpf_prog_load,下面是源码阅读笔记(通过注释的方式学习 ebpf load 的整体逻辑):
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr)
{
enum bpf_prog_type type = attr->prog_type;
struct bpf_prog *prog, *dst_prog = NULL;
struct btf *attach_btf = NULL;
int err;
char license[128];
bool is_gpl;
if (CHECK_ATTR(BPF_PROG_LOAD))
return -EINVAL;
if (attr->prog_flags & ~(BPF_F_STRICT_ALIGNMENT |
BPF_F_ANY_ALIGNMENT |
BPF_F_TEST_STATE_FREQ |
BPF_F_SLEEPABLE |
BPF_F_TEST_RND_HI32 |
BPF_F_XDP_HAS_FRAGS))
return -EINVAL;
if (!IS_ENABLED(CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS) &&
(attr->prog_flags & BPF_F_ANY_ALIGNMENT) &&
!bpf_capable())
return -EPERM;
/* 1.1 根据 attr->license 地址,从用户空态拷贝 license 字符串到内核 */
if (strncpy_from_bpfptr(license,
make_bpfptr(attr->license, uattr.is_kernel),
sizeof(license) - 1) < 0)
return -EFAULT;
license[sizeof(license) - 1] = 0;
/* 1.2 判断 license 是否是 GPL 协议*/
is_gpl = license_is_gpl_compatible(license);
/* 1.3 判断 bpf 程序的总指令数量是否超过最大值 */
if (attr->insn_cnt == 0 ||
attr->insn_cnt > (bpf_capable() ? BPF_COMPLEXITY_LIMIT_INSNS : BPF_MAXINSNS))
return -E2BIG;
/* 1.4 对于 bpf 程序类型不是 BPF_PROG_TYPE_SOCKET_FILTER,BPF_PROG_TYPE_SOCKET_FILTER 的需要管理员权限 */
if (type != BPF_PROG_TYPE_SOCKET_FILTER &&
type != BPF_PROG_TYPE_CGROUP_SKB &&
!bpf_capable())
return -EPERM;
/* 1.5 还有几个权限相关的判断,这里没有具体研究 */
if (is_net_admin_prog_type(type) && !capable(CAP_NET_ADMIN) && !capable(CAP_SYS_ADMIN))
return -EPERM;
if (is_perfmon_prog_type(type) && !perfmon_capable())
return -EPERM;
/* 1.6 检查具体是 bpf prog 还是 btf */
/* attach_prog_fd/attach_btf_obj_fd can specify fd of either bpf_prog
* or btf, we need to check which one it is
*/
if (attr->attach_prog_fd) {
dst_prog = bpf_prog_get(attr->attach_prog_fd);
if (IS_ERR(dst_prog)) {
dst_prog = NULL;
attach_btf = btf_get_by_fd(attr->attach_btf_obj_fd);
if (IS_ERR(attach_btf))
return -EINVAL;
if (!btf_is_kernel(attach_btf)) {
/* attaching through specifying bpf_prog's BTF
* objects directly might be supported eventually
*/
btf_put(attach_btf);
return -ENOTSUPP;
}
}
} else if (attr->attach_btf_id) {
/* fall back to vmlinux BTF, if BTF type ID is specified */
attach_btf = bpf_get_btf_vmlinux();
if (IS_ERR(attach_btf))
return PTR_ERR(attach_btf);
if (!attach_btf)
return -EINVAL;
btf_get(attach_btf);
}
/* 1.7 对于特殊的 attach 类型进行处理,如 BPF_PROG_TYPE_CGROUP_SOCK 为支持需要改为 BPF_CGROUP_INET_SOCK_CREATE */
bpf_prog_load_fixup_attach_type(attr);
if (bpf_prog_load_check_attach(type, attr->expected_attach_type,
attach_btf, attr->attach_btf_id,
dst_prog)) {
if (dst_prog)
bpf_prog_put(dst_prog);
if (attach_btf)
btf_put(attach_btf);
return -EINVAL;
}
/* 2.1 根据 BPF 指令数分配 bpf_prog 空间,和 bpf_prog->aux 空间 */
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);
if (!prog) {
if (dst_prog)
bpf_prog_put(dst_prog);
if (attach_btf)
btf_put(attach_btf);
return -ENOMEM;
}
prog->expected_attach_type = attr->expected_attach_type;
prog->aux->attach_btf = attach_btf;
prog->aux->attach_btf_id = attr->attach_btf_id;
prog->aux->dst_prog = dst_prog;
prog->aux->offload_requested = !!attr->prog_ifindex;
prog->aux->sleepable = attr->prog_flags & BPF_F_SLEEPABLE;
prog->aux->xdp_has_frags = attr->prog_flags & BPF_F_XDP_HAS_FRAGS;
err = security_bpf_prog_alloc(prog->aux);
if (err)
goto free_prog;
prog->aux->user = get_current_user();
prog->len = attr->insn_cnt;
err = -EFAULT;
/* 2.2 把BPF代码从用户空间地址attr->insns,拷贝到内核空间地址prog->insns */
if (copy_from_bpfptr(prog->insns,
make_bpfptr(attr->insns, uattr.is_kernel),
bpf_prog_insn_size(prog)) != 0)
goto free_prog_sec;
prog->orig_prog = NULL;
prog->jited = 0;
/* 2.3 增加 bpf prog 的引用数,用于 bpf 程序的生命周期管理 */
atomic64_set(&prog->aux->refcnt, 1);
prog->gpl_compatible = is_gpl ? 1 : 0;
/* 2.4 bpf 支持设备绑定,这个不是很懂 */
if (bpf_prog_is_dev_bound(prog->aux)) {
err = bpf_prog_offload_init(prog, attr);
if (err)
goto free_prog_sec;
}
/* 2.5 根据attr->prog_type指定的type值,找到对应的bpf_prog_types,
* 给bpf_prog->aux->ops赋值,这个ops是一个函数操作集
*/
/* find program type: socket_filter vs tracing_filter */
err = find_prog_type(type, prog);
if (err < 0)
goto free_prog_sec;
prog->aux->load_time = ktime_get_boottime_ns();
err = bpf_obj_name_cpy(prog->aux->name, attr->prog_name,
sizeof(attr->prog_name));
if (err < 0)
goto free_prog_sec;
/* 3. 使用 verifier 对 bpf 程序进行校验 */
/* run eBPF verifier */
err = bpf_check(&prog, attr, uattr);
if (err < 0)
goto free_used_maps;
/* 4. 对 bpf prog 进行 JIT 转换 */
prog = bpf_prog_select_runtime(prog, &err);
if (err < 0)
goto free_used_maps;
/* 5. 给 bpf prog 分配 id(fd),到这里整个 bpf 程序就算加载完成了 */
err = bpf_prog_alloc_id(prog);
if (err)
goto free_used_maps;
/* Upon success of bpf_prog_alloc_id(), the BPF prog is
* effectively publicly exposed. However, retrieving via
* bpf_prog_get_fd_by_id() will take another reference,
* therefore it cannot be gone underneath us.
*
* Only for the time /after/ successful bpf_prog_new_fd()
* and before returning to userspace, we might just hold
* one reference and any parallel close on that fd could
* rip everything out. Hence, below notifications must
* happen before bpf_prog_new_fd().
*
* Also, any failure handling from this point onwards must
* be using bpf_prog_put() given the program is exposed.
*/
bpf_prog_kallsyms_add(prog);
perf_event_bpf_event(prog, PERF_BPF_EVENT_PROG_LOAD, 0);
bpf_audit_prog(prog, BPF_AUDIT_LOAD);
err = bpf_prog_new_fd(prog);
if (err < 0)
bpf_prog_put(prog);
return err;
free_used_maps:
/* In case we have subprogs, we need to wait for a grace
* period before we can tear down JIT memory since symbols
* are already exposed under kallsyms.
*/
__bpf_prog_put_noref(prog, prog->aux->func_cnt);
return err;
free_prog_sec:
free_uid(prog->aux->user);
security_bpf_prog_free(prog->aux);
free_prog:
if (prog->aux->attach_btf)
btf_put(prog->aux->attach_btf);
bpf_prog_free(prog);
return err;
}
Public discussion