golang map 类型实现原理研究
结合 golang 的源码,借助 gdb debug 技术手段深入追踪 go runtime 对于复杂的 map 类型是如何进行内存布局的,根据总结的 golang map 内存布局总结 ebpf uprobe 获取 map 参数的思路

根据 golang 源码(runtime/map.go)关于 map 类型的定义,借助 gdb debug 技术手段深入追踪 go runtime 对于复杂的 map 类型是如何进行内存布局的,在对 map 类型有了深入了解之后再总结一下 ebpf 获取 map 变量内存的步骤。
go map struct
map header
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
| 字段 | 解释 |
|---|---|
| count | 键值对的数量 |
| B | 2^B=len(buckets) |
| hash0 | hash因子 |
| buckets | 指向一个数组(连续内存空间),数组的类型为[]bmap,bmap类型就是存在键值对的结构下面会详细介绍,这个字段我们可以称之为正常桶。如下图所示 |
| oldbuckets | 扩容时,存放之前的buckets(Map扩容相关字段) |
| extra | 溢出桶结构,正常桶里面某个bmap存满了,会使用这里面的内存空间存放键值对 |
| noverflow | 溢出桶里bmap大致的数量 |
| nevacuate | 分流次数,成倍扩容分流操作计数的字段(Map扩容相关字段) |
| flags | 状态标识,比如正在被写、buckets和oldbuckets在被遍历、等量扩容(Map扩容相关字段) |
map bucket
map bucket(桶)的结构体原始定义(runtime/map.go):
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
在运行期间,bmap 结构体其实不止包含 tophash 字段,因为哈希表中可能存储不同类型的键值对,而且 Go 语言(1.17之前)也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导。bmap 中的其他字段在运行时也都是通过计算内存地址的方式访问的,所以它的定义中就不包含这些字段。在运行时,bmap 摇身一变,成了下面的样子:
type bmap struct {
tophash [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
| 字段 | 解释 |
|---|---|
| tophash | 长度为8的数组,[]uint8,元素为:map key 获取的 hash 的高8位,遍历时对比使用,提高性能 |
| keys | 长度为8的数组,[]keytype,元素为:具体的 key 值,具体 size 与 map 定义的 key 的类型相关 |
| values | 长度为8的数组,[]elemtype,元素为:key 对应的 value 值,具体 size 与 map 定义的 key 的类型相关 |
| pad | 对齐内存使用的,不是每个 bmap 都有会这个字段,需要满足一定条件 |
| overflow | 指向的 hmap.extra.overflow 溢出桶里的 bmap,上面的字段 tophash、keys、elems 长度为8,最多存8组键值对,存满了就往指向的这个 bmap 里存 |
map overflow bucket
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
| 字段 | 解释 |
|---|---|
| overflow | map 的溢出桶,类型和 hmap.buckets 一样也是数组 []bmap,当正常桶 bmap 存满了的时候就使用 hmap.extra.overflow 的 bmap,bmap 结构里的 bmap.overflow 字段是个指针类型,存放了它对应使用的溢出桶 hmap.extra.overflow 里的 bmap 的地址 |
| oldoverflow | 扩容时存放之前的overflow(Map扩容相关字段) |
| nextOverflow | 指向溢出桶里下一个可以使用的bmap |
map struct detail relation
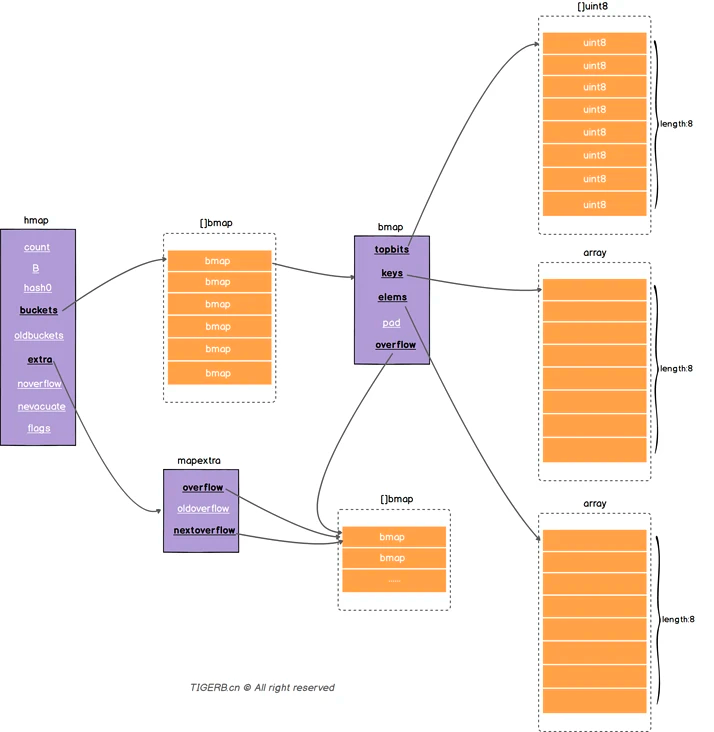
gdb insight go map
test code to check map memory layout
package main
import "fmt"
func test_map(l uint64, m map[string]int, i string) {
fmt.Println(m)
print(&m)
fmt.Println(i)
fmt.Println(&i)
}
func main() {
myMap := make(map[string]int, 53)
myMap["key"] = 1
test_map(333, myMap, "111")
print(myMap["key"])
delete(myMap, "key")
}
gdb cmdline to monitor map memory layout
root@ubuntu-hirsute:~/go/src/go-map-memory#
>> gdb main
GNU gdb (Ubuntu 10.1-2ubuntu2) 10.1.90.20210411-git
Copyright (C) 2021 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from main...
Loading Go Runtime support.
(gdb) b main.test_map
Breakpoint 1 at 0x47eae0: file /root/go/src/go-map-memory/go-map.go, line 5.
(gdb) r
Starting program: /root/go/src/go-map-memory/main
[New LWP 101793]
[New LWP 101794]
[New LWP 101795]
[New LWP 101796]
[New LWP 101797]
Thread 1 "main" hit Breakpoint 1, main.test_map (l=333, m=map[string]int = {...}, i="111") at /root/go/src/go-map-memory/go-map.go:5
5 func test_map(l uint64, m map[string]int, i string) {
(gdb) info reg
rax 0x14d 333
rbx 0xc000070150 824634179920
rcx 0x494908 4802824
rdx 0x488800 4753408
rsi 0x0 0
rdi 0x3 3
rbp 0xc00006cf70 0xc00006cf70
rsp 0xc00006cf30 0xc00006cf30
r8 0xc00007b000 824634224640
r9 0x49494a 4802890
r10 0x0 0
r11 0xc00007b000 824634224640
r12 0x203000 2109440
r13 0x49c6c0 4835008
r14 0xc0000001a0 824633721248
r15 0x7fffd1488602 140736704579074
rip 0x47eae0 0x47eae0 <main.test_map>
eflags 0x246 [ PF ZF IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
(gdb) x/40bx 0xc00006cf30
0xc00006cf30: 0x94 0xed 0x47 0x00 0x00 0x00 0x00 0x00
0xc00006cf38: 0x00 0x88 0x48 0x00 0x00 0x00 0x00 0x00
0xc00006cf40: 0x50 0x01 0x07 0x00 0xc0 0x00 0x00 0x00
0xc00006cf48: 0x4a 0x49 0x49 0x00 0x00 0x00 0x00 0x00
0xc00006cf50: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00
(gdb) n
6 fmt.Println(m)
(gdb) x/40bx 0xc00006cf30
0xc00006cf30: 0x94 0xed 0x47 0x00 0x00 0x00 0x00 0x00
0xc00006cf38: 0x4d 0x01 0x00 0x00 0x00 0x00 0x00 0x00
0xc00006cf40: 0x50 0x01 0x07 0x00 0xc0 0x00 0x00 0x00
0xc00006cf48: 0x08 0x49 0x49 0x00 0x00 0x00 0x00 0x00
0xc00006cf50: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00
(gdb) x/48bx 0xc000070150
0xc000070150: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070158: 0x00 0x04 0x00 0x00 0xb1 0x29 0x55 0xc2
0xc000070160: 0x00 0xb0 0x07 0x00 0xc0 0x00 0x00 0x00
0xc000070168: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070170: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070178: 0x30 0xc0 0x00 0x00 0xc0 0x00 0x00 0x00
(gdb) x/144bx 0xc00007b000
0xc00007b000: 0x23 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b008: 0x4a 0x49 0x49 0x00 0x00 0x00 0x00 0x00
0xc00007b010: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b018: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b020: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b028: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b030: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b038: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b040: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b048: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b050: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b058: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b060: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b068: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b070: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b078: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b080: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b088: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
(gdb) x/3cb 0x49494a
0x49494a: 107 'k' 101 'e' 121 'y'
(gdb) p *(0xc00007b008+16*8)
$1 = 1
(gdb)
map memory size
hmap size
根据上一节 gdb 的分析可以看出 map 变量的大小是 48 字节(即 hmap size):
# func test_map(l uint64, m map[string]int, i string) called
# test_map(333, myMap, "111")
#
(gdb) x/40bx 0xc00006cf30
# pt_regs->sp
0xc00006cf30: 0x94 0xed 0x47 0x00 0x00 0x00 0x00 0x00
# pt_regs->sp + 8, l uint64 = 333
0xc00006cf38: 0x4d 0x01 0x00 0x00 0x00 0x00 0x00 0x00
# pt_regs->sp + 16, m map[string]int address
0xc00006cf40: 0x50 0x01 0x07 0x00 0xc0 0x00 0x00 0x00
# pr_regs->sp + 24, i string(.data) = "111"
0xc00006cf48: 0x08 0x49 0x49 0x00 0x00 0x00 0x00 0x00
# pr_regs->sp + 32, i string(.len) = 3
0xc00006cf50: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00
# m map[string]int memory
(gdb) x/48bx 0xc000070150
# m.count = 1
0xc000070150: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
# m.flags = 0
# m.B = 4
# m.noverflow = 0
# m.hash0 = 0xc25529b1
0xc000070158: 0x00 0x04 0x00 0x00 0xb1 0x29 0x55 0xc2
# m.buckets = 0xc00007b000
0xc000070160: 0x00 0xb0 0x07 0x00 0xc0 0x00 0x00 0x00
# m.oldbuckets = 0x0
0xc000070168: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
# m.nevacuate = 0x0
0xc000070170: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
# m.extra = 0xc00000c030
0xc000070178: 0x30 0xc0 0x00 0x00 0xc0 0x00 0x00 0x00
bmap size
map[string]int 定义了 map key 和 value 具体类型,这些也将决定 bmap size:
map[string]int bmap size:
8 + # tophash
16 * 8 + # key[8]
8 * 8 + # value[8]
8 # overflow bmap pointer
= 208
# check bmap memory layout with the help of gdb debugging
(gdb) x/48bx 0xc000070150
0xc000070150: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070158: 0x00 0x04 0x00 0x00 0xb1 0x29 0x55 0xc2
0xc000070160: 0x00 0xb0 0x07 0x00 0xc0 0x00 0x00 0x00
0xc000070168: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070170: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc000070178: 0x30 0xc0 0x00 0x00 0xc0 0x00 0x00 0x00
# m.buckets = 0xc00007b000 (go runtime setup the memory as bmap)
(gdb) x/144bx 0xc00007b000
0xc00007b000: 0x23 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xc00007b008: 0x4a 0x49 0x49 0x00 0x00 0x00 0x00 0x00 --- key |
0xc00007b010: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b018: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b020: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b028: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b030: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b038: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b040: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b048: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 offset 8 keys
0xc00007b050: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b058: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b060: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b068: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b070: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b078: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b080: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
0xc00007b088: 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00 --- value|
map memory layout
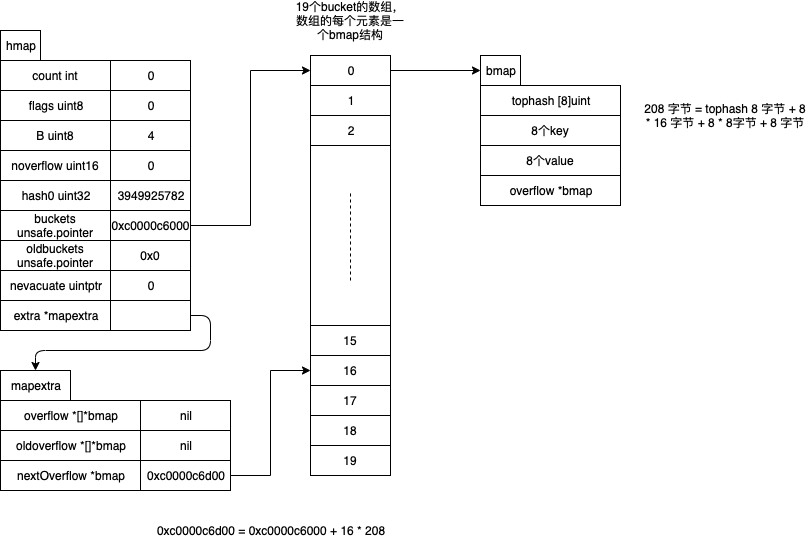
+--------------+ +-----------------------------------+
| | | |
| go map param +---> count |
| | | |
+--------------+ +-------+---------+---------+-------+
| | | | |
| flags | B | hash0 |
| | | | |
+-------+---------+---------+-------+ +----------------+
| | | |
| buckets +----------------> bmap[0] |
| | | |
+-----------------------------------+ +----------------+
| | | |
| oldbuckets | | bmap[1] |
| | | |
+-----------------------------------+ +----------------+
| | | |
| nevacuate | | |
| | | |
+-----------------------------------+ | . |
| | | . |
| extra | | . |
| | | |
+-----------------------------------+ | |
+----------------+
bmap[0] | |
+-----------------------+ | bmap[2^B+1] |
| | | |
| tophash | +----------------+
| | | |
+-----------------------+ | overflow+bmap |
| | | |
| key[0] | | . |
+-----------------------+ | . |
| | | . |
| . . . | | |
+-----------------------+ +----------------+
| |
| key[7] |
+-----------------------+
| |
| value[0] |
+-----------------------+
| |
| . . . |
+-----------------------+
| |
| value[7] |
+-----------------------+
| |
| pad |
+-----------------------+
| |
| overflow |
+-----------------------+go map runtime
这里是 go runtime 具体是怎么操作 map 类型的,内容比较复杂这里只是简单的列举初相关的源码。
🔔
TODO: 后续再做详细理解,特别是 golang map 扩容操作
init
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 判断 hint 是否合法
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
// 找到满足 loadFactor * 2^B >= hint 的 B,其中 loadFactor = loadFactorNum / loadFactorDen = 13 / 2 = 6.5
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
// makeBucketArray 中会判断 h.B 是否 >= 4,如果是,则会分配 nextOverflow,即overflow bucket
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
assign
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(unsafe.Pointer(h), callerpc, funcPC(mapassign_faststr))
}
// 不允许并发写
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
key := stringStructOf(&s)
// 调用key类型对应的hash算法
hash := t.key.alg.hash(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))
// Set hashWriting after calling alg.hash for consistency with mapassign.
// 异或操作,设置写标记位
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 计算key存储在哪个bucket
bucket := hash & bucketMask(h.B)
if h.growing() {
// 如果map正在扩容,需要确保bucket已经被搬运到hmap.buckets中了
growWork_faststr(t, h, bucket)
}
// 取得对应bucket的内存地址
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
// 取hash的高8位
top := tophash(hash)
// 实际插入的bucket,虽然上面计算出了b,但可能b已经满了,需要插入到b的overflow bucket,或者map需要扩容了
var insertb *bmap
// 插入到bucket中的哪个位置
var inserti uintptr
// bucket中key的地址
var insertk unsafe.Pointer
bucketloop:
for {
// bucketCnt = 8
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && insertb == nil { // 在b中找到位置i可以存放赋值的KV
insertb = b
inserti = i
// 为何这里不执行break bucketloop?因为有可能K已经存在,需要找到它的位置
}
// 如果余下的位置都是空的,则不需要再往下找了
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash 相同,还需要仔细比较实际的K是否一样
k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*sys.PtrSize))
if k.len != key.len {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
// K已经在map中了
// already have a mapping for key. Update it.
inserti = i
insertb = b
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// K不在map中,需要判断是否进行扩容或者增加overflow bucket
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
// 如果map没有扩容,并且负载因子超过阈值或者有太多overflow bucket,则进行扩容
hashGrow(t, h)
// 跳转回again
goto again // Growing the table invalidates everything, so try again
}
// 如果还是没找到空闲的位置存放新的KV,则需要存储到overflow bucket中
if insertb == nil {
// all current buckets are full, allocate a new one.
insertb = h.newoverflow(t, b)
inserti = 0 // not necessary, but avoids needlessly spilling inserti
}
insertb.tophash[inserti&(bucketCnt-1)] = top // mask inserti to avoid bounds checks
// 插入K
insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*sys.PtrSize)
// store new key at insert position
*((*stringStruct)(insertk)) = *key
h.count++
done:
// 获取V的地址
elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*2*sys.PtrSize+inserti*uintptr(t.elemsize))
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 清除写标记位
h.flags &^= hashWriting
// 返回V的地址,实际赋值是由编译器生成的汇编代码进行赋值的
return elem
}
access
func mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool) {
if raceenabled && h != nil {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapaccess2_faststr))
}
// 返回零值,已经false,表示key不存在
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
key := stringStructOf(&ky)
if h.B == 0 {
// 只有1个bucket
// One-bucket table.
b := (*bmap)(h.buckets)
if key.len < 32 {
// key比较短,直接进行比较
// short key, doing lots of comparisons is ok
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*sys.PtrSize) {
k := (*stringStruct)(kptr)
if k.len != key.len || isEmpty(b.tophash[i]) {
// 后面已经没有KV了,不用再找下去了
if b.tophash[i] == emptyRest {
break
}
continue
}
// 找到key
if k.str == key.str || memequal(k.str, key.str, uintptr(key.len)) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*sys.PtrSize+i*uintptr(t.elemsize)), true
}
}
// 未找到,返回零值
return unsafe.Pointer(&zeroVal[0]), false
}
// key 比较长
// long key, try not to do more comparisons than necessary
keymaybe := uintptr(bucketCnt)
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*sys.PtrSize) {
k := (*stringStruct)(kptr)
if k.len != key.len || isEmpty(b.tophash[i]) {
// 后面已经没有KV了,不用再找下去了
if b.tophash[i] == emptyRest {
break
}
continue
}
// 找到了,内存地址一样
if k.str == key.str {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*sys.PtrSize+i*uintptr(t.elemsize)), true
}
// 检查头4字节
// check first 4 bytes
if *((*[4]byte)(key.str)) != *((*[4]byte)(k.str)) {
continue
}
// 检查尾4字节
// check last 4 bytes
if *((*[4]byte)(add(key.str, uintptr(key.len)-4))) != *((*[4]byte)(add(k.str, uintptr(key.len)-4))) {
continue
}
// 走到这里,说明有至少2个key有可能匹配
if keymaybe != bucketCnt {
// Two keys are potential matches. Use hash to distinguish them.
goto dohash
}
keymaybe = i
}
// 有1个key可能匹配
if keymaybe != bucketCnt {
k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+keymaybe*2*sys.PtrSize))
if memequal(k.str, key.str, uintptr(key.len)) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*sys.PtrSize+keymaybe*uintptr(t.elemsize)), true
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
dohash:
hash := t.key.alg.hash(noescape(unsafe.Pointer(&ky)), uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 判断是否正在扩容
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
// 如果不是相同大小的扩容,则需要缩小一倍,因为此时 len(h.buckets) = 2*len(h.oldbuckets)
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 判断对应的bucket是否已经从h.oldbuckets搬到h.buckets
if !evacuated(oldb) {
// 还没有搬
b = oldb
}
}
top := tophash(hash)
// 在b,以及b的overflow bucket中查找
for ; b != nil; b = b.overflow(t) {
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*sys.PtrSize) {
k := (*stringStruct)(kptr)
if k.len != key.len || b.tophash[i] != top {
continue
}
if k.str == key.str || memequal(k.str, key.str, uintptr(key.len)) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*sys.PtrSize+i*uintptr(t.elemsize)), true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
delete
func mapdelete_faststr(t *maptype, h *hmap, ky string) {
if raceenabled && h != nil {
callerpc := getcallerpc()
racewritepc(unsafe.Pointer(h), callerpc, funcPC(mapdelete_faststr))
}
if h == nil || h.count == 0 {
return
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
key := stringStructOf(&ky)
hash := t.key.alg.hash(noescape(unsafe.Pointer(&ky)), uintptr(h.hash0))
// Set hashWriting after calling alg.hash for consistency with mapdelete
h.flags ^= hashWriting
bucket := hash & bucketMask(h.B)
// 如果正在扩容,确保bucket已经从h.oldbuckets搬到h.buckets
if h.growing() {
growWork_faststr(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
// 在b,已经b的overflow bucket中查找
for ; b != nil; b = b.overflow(t) {
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*sys.PtrSize) {
k := (*stringStruct)(kptr)
if k.len != key.len || b.tophash[i] != top {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
// 找到了
// Clear key's pointer.
k.str = nil
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*2*sys.PtrSize+i*uintptr(t.elemsize))
// 与GC相关
if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 标记当前单元是空闲的
b.tophash[i] = emptyOne
// If the bucket now ends in a bunch of emptyOne states,
// change those to emptyRest states.
// 判断>i的单元是否都是空闲的
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
// >i的单元都是空闲的,那么将当前单元,以及<i的emptyOne单元都标记为emptyRest
// emptyRest的作用就是在查找的时候,遇到emptyRest就不用再往下找了,加速查找的过程
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
h.count--
break search
}
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
grow
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
// 如果装载因子没有超过阈值,那么按相同大小的空间“扩容”
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 分配新空间
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// 清除 iterator,oldIterator 的标记位
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0 // 统计搬了多少个bucket
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
// 插入和删除的时候,发现正在扩容的话,会调用该方法
func growWork_faststr(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate_faststr(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate_faststr(t, h, h.nevacuate)
}
}
func evacuate_faststr(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
// 判断该bucket是否已经搬迁了
if !evacuated(b) {
// TODO: reuse overflow buckets instead of using new ones, if there
// is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations.
// xy 指向新空间的高低区间的起点
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*2*sys.PtrSize)
// 如果是扩容一倍,才会用到 y
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*2*sys.PtrSize)
}
// 将当前 bucket 以及其 overflow bucket 进行搬迁
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*2*sys.PtrSize)
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, 2*sys.PtrSize), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
// 这里是不是可以判断到 emptyRest 就停止循环了?
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.key.alg.hash(k, uintptr(h.hash0))
if hash&newbit != 0 { // 新的位置位于高区间
useY = 1
}
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY, enforced in makemap
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt { // 是否要放到 overflow bucket 中
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*2*sys.PtrSize)
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// Copy key.
*(*string)(dst.k) = *(*string)(k)
typedmemmove(t.elem, dst.e, e)
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, 2*sys.PtrSize)
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
// 统计搬迁的进度,如果数据都搬迁完了,则结束扩容
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
ebpf fetch k-v from go map
- 获取 map 地址
var_map_addr = pt_regs->sp + offset; - 获取正常桶地址
map_buckets_addr = var_map_addr + 16; - 获取 map len
map_len = *(int*)var_map_addr; - 获取 buckets 数量
buckets_num = 1 << *(*uint8)(var_map_addr + 8 + 1); - 从 map_buckets_addr 遍历 buckets_num 个 bmap 将非 0 的 k-v 读取出来;
- 如果步骤5中的获取的 k-v 数量 与 map_len 不相等,再遍历每一个 overflow 指向的 bmap(bmap 结构最后 8 字节代表溢出桶的地址);
Public discussion