markdown 字数统计工具设计
Obsidian DataView 插件没有现成的统计字数的接口,期望有一个这样的工具来帮助统计文本中的字数特别是 CJK,从而萌生了进行这样一个小工具开发的想法
产品原型
1. background
在 Obsidian 笔记过程中想通过 DataView 插件进行博客运维日志的统计,当前的统计情况如下图所示:
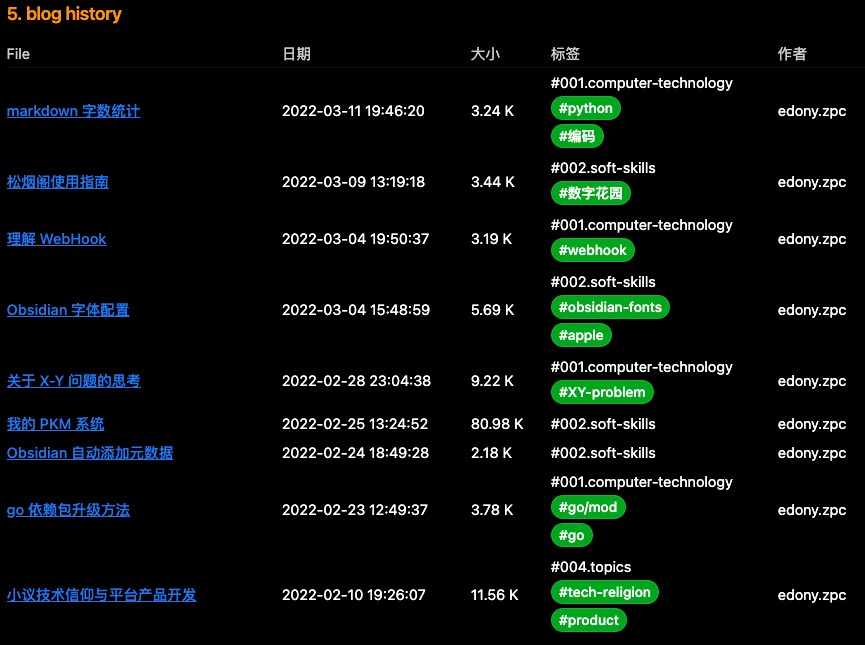
对于大小这一栏,最初的想法是统计文档的字数,无赖目前 DataView 插件没有现成的接口,期望有一个这样的工具来帮助统计文本中的字数,进而萌生了进行这样一个小工具开发的想法。
2. ideas
2.1 问题边界
要想打开一个文本文件就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。所以要统计一个 markdown 文件的字数,有一个前提就是知道文档的编码格式,目前我常用的 markdown 文本主要有英文,中文,emoji,所以 MVP 的时候可以做简化假设文本的编码格式是 utf-8。
2.2 问题思路
- 以
utf-8编码格式读取 markdown 文本; - 确定需要统计的字符的
unicode范围;
- 中文:
[u4e00-u9fa5] - 中文符号:
[u3000-u303f],[ufb00-ufffd] - 英文字符:
[a-z],[A-Z] - 空格符:
[ \t\n\r\f\v]
- 通过正则表达统计符合各自范围内的字符个数;
2.3 遗留问题
- 对于一个普通的文本文档,编码格式是什么需要确定,例如 GBK、GB2312 等编码格式;
unicode编码范围细化,需要看 CJK 的编码范围,这样才能更加准确的统计;- 通过正则表达的方式确认属于那种字符,是否有性能优化的空间;
- 怎么集成使用这个小工具;
3. user portrait
用户画像就是回答一个问题:谁想怎么使用这个项目达到什么目的?
3.1 谁会使用
想统计文本文档字数的人。
在这里我自己再追加问了一个问题:想统计这个数据的人为什么需要看这个统计数字?这个统计数字是当前文本文档的一个状态,对这个状态比较好奇的人大致分为两类:
- 写这个文档的人;写文档的人关注文档的统计数据,本质是想清楚向前的写做的状态,所以更加倾向于工具无缝集成到自己的写作工作流中
- 读这个文档的人;读这个文档的人,可能只是出于想了解,或者管理需要等,好用的独立工具也能够接受
3.2 怎么使用
- 单独统计
- 集成到工作流中
3.3 什么价值
- 提升编写、管理文档的效率(⚠️有点牵强)
- 丰富文档的元数据,用于展示和了解
MVP 源码
#! /usr/bin/python3
# -*- coding: utf-8 -*-
import string
import os
import io
import re
def str_count(s):
count_en = count_dg = count_sp = count_zh = count_pu = 0
s_len = len(s)
for c in s:
# 统计英文
if c in string.ascii_letters:
count_en += 1
# 统计数字
elif c.isdigit():
count_dg += 1
# 统计空格
elif c.isspace():
count_sp += 1
# 统计中文
elif c.isalpha():
count_zh += 1
# 统计特殊字符
else:
count_pu += 1
total_chars = count_zh + count_en + count_sp + count_dg + count_pu
if total_chars == s_len:
return ('总字数:{0},中文字数:{1},英文字数:{2},空格:{3},数字数:{4},标点符号:{5}'.format(s_len, count_zh, count_en, count_sp, count_dg, count_pu))
class MarkdownCounter:
def __init__(self, filename):
self.filename = filename
self.__zh_pattern = u"[\u4e00-\u9fa5]"
self.__zh_punctuation = u"[\u3000-\u303f\ufb00-\ufffd]"
self.__en_pattern = u"[A-Za-z]"
self.__digital_pattern = u"[0-9]"
self.__whitespace = u"[ \t\n\r\f\v]"
self.__others_pattern = "(?!" + self.__zh_pattern + "|" + self.__zh_punctuation + "|" + self.__en_pattern + "|" + self.__digital_pattern + "|" + self.__whitespace + ")"
def __read_file(self):
with io.open(self.filename, mode='r', encoding='utf-8') as md_file:
self.content = md_file.read()
def count_words(self):
self.__read_file()
unicode_content = self.content
re.split
zh_content = re.findall(self.__zh_pattern, unicode_content)
zh_punc_content = re.findall(self.__zh_punctuation, unicode_content)
en_content = re.findall(self.__en_pattern, unicode_content)
dig_content = re.findall(self.__digital_pattern, unicode_content)
whitespace_content = re.findall(self.__whitespace, unicode_content)
others_content = re.findall(self.__others_pattern, unicode_content)
self.zh_len, self.zh_punc_len, self.en_len, self.digital_len, self.whitespace_len, self.others_len = len(zh_content), len(zh_punc_content), len(en_content), len(dig_content), len(
whitespace_content), len(others_content)
if __name__ == "__main__":
print("markdown word counter!")
print(os.getcwd())
with io.open("test.md", mode='r', encoding='utf-8') as md_file:
buffer = md_file.read()
out = str_count(buffer)
buffer_unicode = buffer.encode('utf-8')
counter = MarkdownCounter("test.md")
counter.count_words()
print(counter.content.encode('utf-8'))
print("中文: {}, 中文标点: {}, 英文: {}, 数字: {}, 空格: {}, 其他: {}".format(counter.zh_len, counter.zh_punc_len, counter.en_len, counter.digital_len, counter.whitespace_len, counter.others_len))
Github repo:https://github.com/edonyzpc/side-projects/tree/master/markdown-word-counter
Public discussion