
ReAct Agent + MCP实现有声书转换
本文介绍了使用MCP和LLM Agent技术将电子书转换为有声书的过程,包括需求分析、技术可行性、业务价值考量及具体实现细节。主要解决了MCP工具返回内容超限问题和Cosyvoice模型文本长度限制问题。

开始技术细节之前,关于有声书想多絮叨两句(也算是一种产品需求分析):
- 有声书的主要需求来源:
- 随着生活节奏加快,人们越来越依赖碎片时间获取信息,有声书允许用户在通勤、做家务、运动等场景中同步进行 “阅读”;
- 特殊人群的阅读需求,老人、视障等天然存在阅读困难的人,儿童等尚需启蒙的人群等都需要借助有声书来“阅读”;
- 情感陪伴与心理健康支持需求,声音的陪伴属性使其成为心理健康的 “软支撑”,睡前听书还可能通过影响梦境内容(如高频 β 波激活记忆)间接改善心理状态,广播剧、小说等内容通过角色演绎引发情感共振。
- 技术可行性:
- 丰富的kindle、z-library等电子书资源提供了高质量的有声书文本资源;
- AI 技术(如 TTS 语音合成)大幅降低制作成本;
- MCP协议生态的丰富大大增强了AI的能力边界;
- 从业务价值的角度做这件事情是有待商榷的:
- 已经有喜马拉雅这样平台了,折腾有声书转换的必要性不高;
- 已经有NotebookLM了,自己去开发基于LLM的工具必要性不高;
- 平台和工具皆有竟品的情况下,这件事情的效率和性价比都会有问题,所以这个项目只能是个人兴趣和副业;
基于上述的分析,打算用MCP Servers + LLM实现将电子书转换为有声书的小工具,使用方式很简单在AI交互框中输入“将xxx目录中xxx转为成音频”,这样我就拥有了一个低配版的喜马拉雅,将任意自己喜欢电子书变成自己和家人喜欢的有声书了。
技术思路
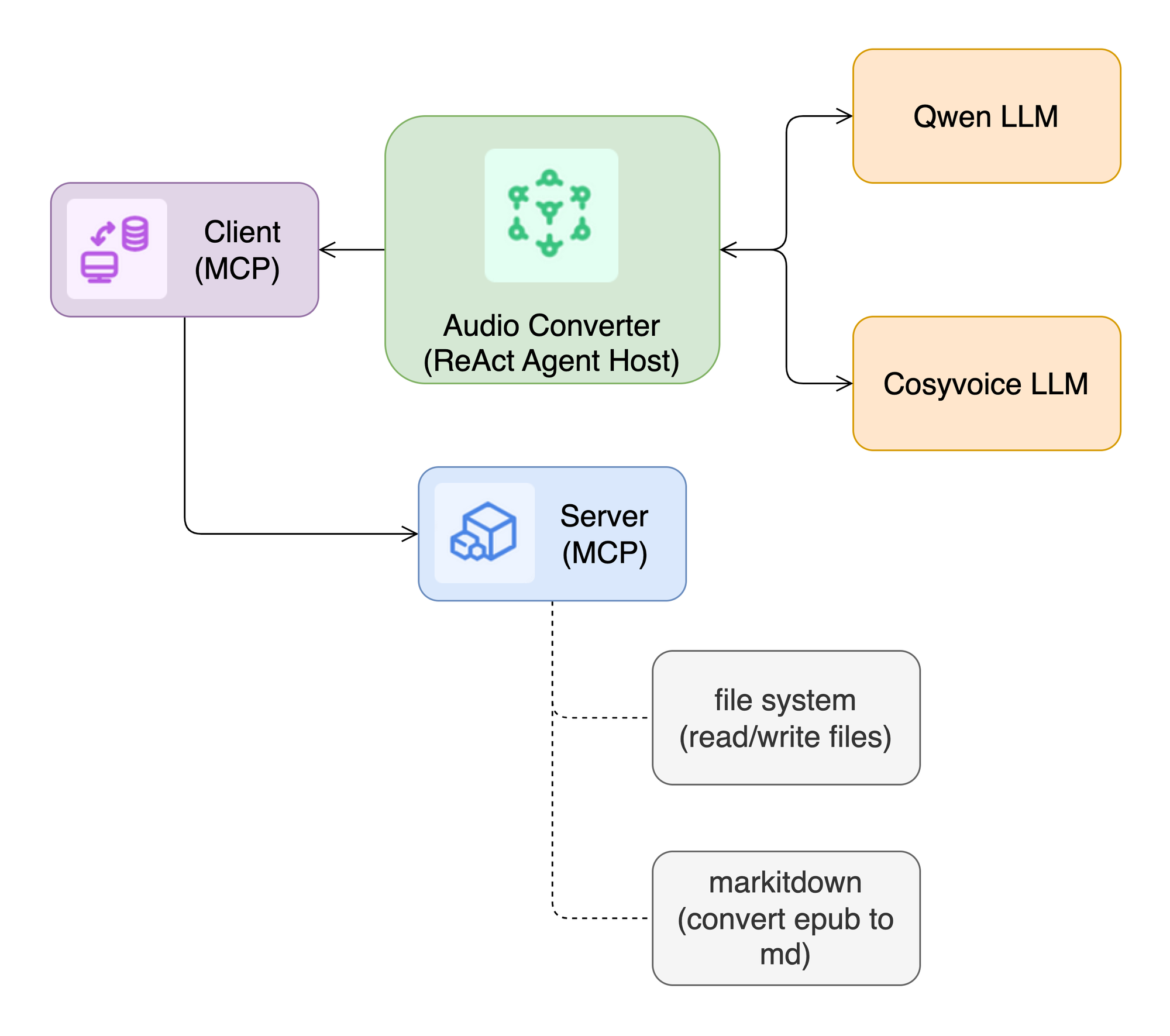
- 首先创建一个ReAct Agent(即构建一个由LLM到Tools的State Graph),该Agent用于规划有声书转换的任务
- 根据Agent规划任务调用file system进行相关文件的读写操作
- 根据Agent规划任务调用Markitdown MCP将电子书(如epub、docx、pdf等文件)转换成markdown文本
- 根据Agent规划任务将转换之后的markdown批量转换成音频(mp3格式)
实现细节
具体实现比较简单,详细可以参考demo代码在GitHub仓库中 MCP agents,实现过程中我觉得比较有意思的两个细节可以分享一下:
1. MCP Tool返回内容超限问题
我在进行demo测试的时候,用的是海明威的「老人与海」的英文版(约4万字),markitdown mcp调用之后返回大约6万字的markdown文本,正常情况下ReAct Agent会将mcp返回的内容作为LLM的上下文message进行下一轮的任务输入,此时就碰到问题了,明显超出了Qwen的上下文token限制(30,720),此时会直接导致Agent任务执行失败。
再回来分析markitdown mcp调用的结果,ReAct Agent并不需要大模型进行文本处理,所以我们只需要Agent直接返回mcp的结果即可。非常敬佩langchain(langraph)框架,这种细节需求场景都能覆盖到,虽然它饱受诟病。话不多说,直接上代码:
async def convert_epub_to_markdown(self, query: str) -> str:
messages = [{"role": "user", "content": query}]
available_tools = []
# Load tools from all sessions
for session in self.sessions:
tools = await load_mcp_tools(self.sessions[session])
available_tools.extend(tools)
if session == "markitdown-mcp":
# enforce a tool output from an agent avoiding any additional text the the agent adds after the tool call
for tool in tools:
tool.return_direct = True
# logger.debug("Available tools:", available_tools[0])
# Initial Qwen API call
agent = create_react_agent(self.qwen, available_tools)
response = await agent.ainvoke({"messages": query})
# Detailed processing of tool calls if you use other LLM, e.g. Claude
self.__md_str = response["messages"][-1].content
return response["messages"][-1].content
2. Cosyvoice max length问题
Cosyvoice LLM模型有一个限制,在进行文本转语音的时候发送的文本长度不得超过2000字符,这名相不满足「老人与海」有声书转换的要求,为此根据模型max length限制,我将超长文本按照语义和格式进行分割,然后批量进行语音转换。
def split_text(self, text: str, max_length: int = 2000) -> list:
splitter = MarkdownTextSplitter(chunk_size=max_length, chunk_overlap=0)
return splitter.split_text(text)
def exec():
# ...省略一些代码
await client.connect_to_mcp_server("markitdown-mcp")
# await client.connect_to_mcp_server("filesystem-mcp")
response = await client.convert_epub_to_markdown(
"把文件`/Users/edony/Downloads/hemingway-old-man-and-the-sea.epub`转换为markdown格式,大模型不要处理任何markdown,直接输出全部原文"
)
# split_text method
chunks = client.split_text(response, max_length=2000)
batch_size = 10
batch = math.ceil(len(chunks) / batch_size)
for i in range(batch):
sub_chunks = chunks[i * batch_size : (i + 1) * batch_size]
await client.synthesis_text_to_speech_using_asyncio(sub_chunks, i)
logger.info(len(chunks))
效果展示

Public discussion