
小本本系列:o3模型引发一次用好大模型工具的尝试

一个月前随着OpenAI o3的发布,社交媒体上兴起了「根据图片找位置」的潮流,举个简单的例子(来源:NanYi):

一开始我不以为意,我觉得只要能解析图片中Exif信息足够了,不是什么黑科技,直到我看了一下o3的分析过程:
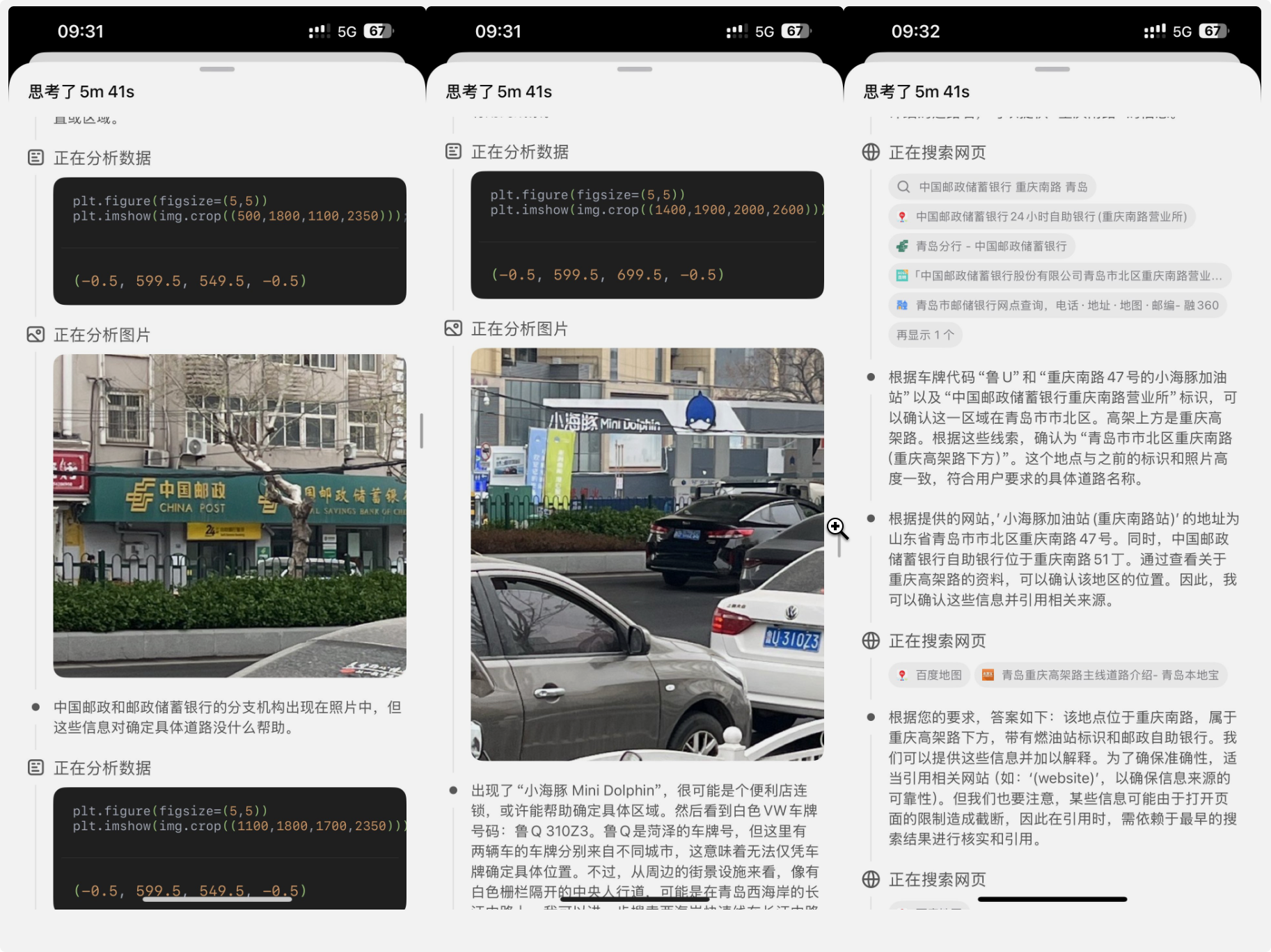
这个分析方法代表着没有metadata的图片也能精确分析得到结果,除了惊讶模型分析推理能力之外,我觉得更加让我惊艳的地方是图片和文字的信息对齐和协同能力 —— 大模型的多模态能力已经不仅仅局限于输入上的多模态支持了。
于是我萌生了一个大胆的想法:作为没有AI算法背景的人打算借助AI工具弄清楚这里的黑科技。
明确研究对象
Multi-Modal 多模态已经不陌生了,但是o3这种多种模态输入信息的联动(对齐)到底是归属哪个范畴,需要先识别出来。经过简单的搜索引擎的检索,发现「弥合不同模态之间的语义差距并确保其表示的有效对齐是Multi-Modal Token需要解决的范畴」。
有了关键信息就比较方便了,分别用「Multi-Modal Token」、「多模态token」、「多模态令牌」等关键词进行检索,发现有大量的论文是做相关研究的。
这么复杂且并非自己熟悉的学术领域,自己一篇论文一篇论文的研究肯定是不可能了,直接上手段 Gemini Deep Research。
Deep Research
目前各家大模型基本陆续都推出了 Deep Research 的功能,我个人还是觉得Gemini的更好用,应该归功于Google多年的搜索引擎技术上的积累。
对于不太熟悉的领域,我需要快速的建立对快内容的认知,于是关于Multi-Modal Token结构化的介绍就是第一步了:
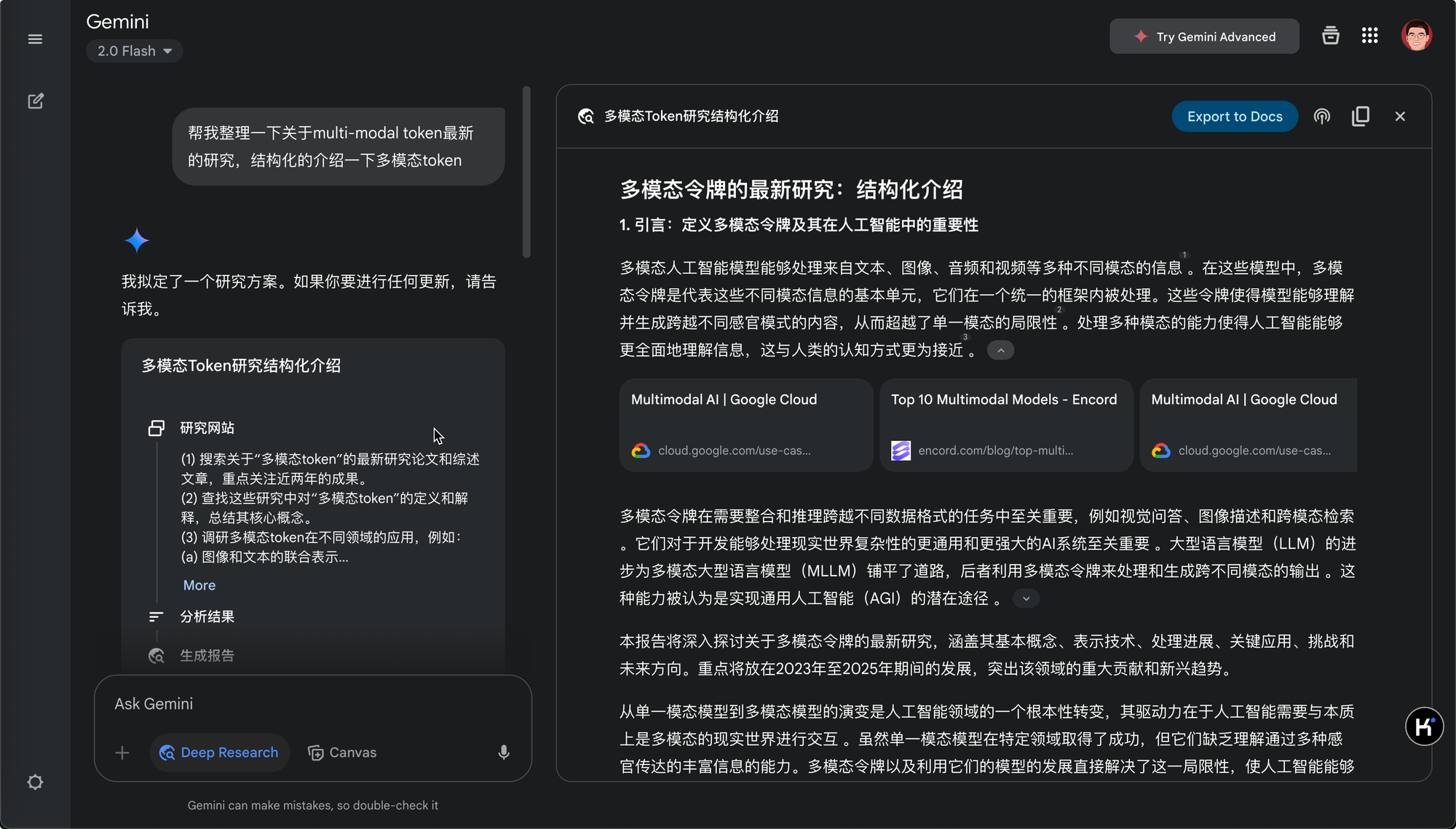
这是Gemini最后给出的分析报告:多模态token研究结构化介绍 - Google Docs
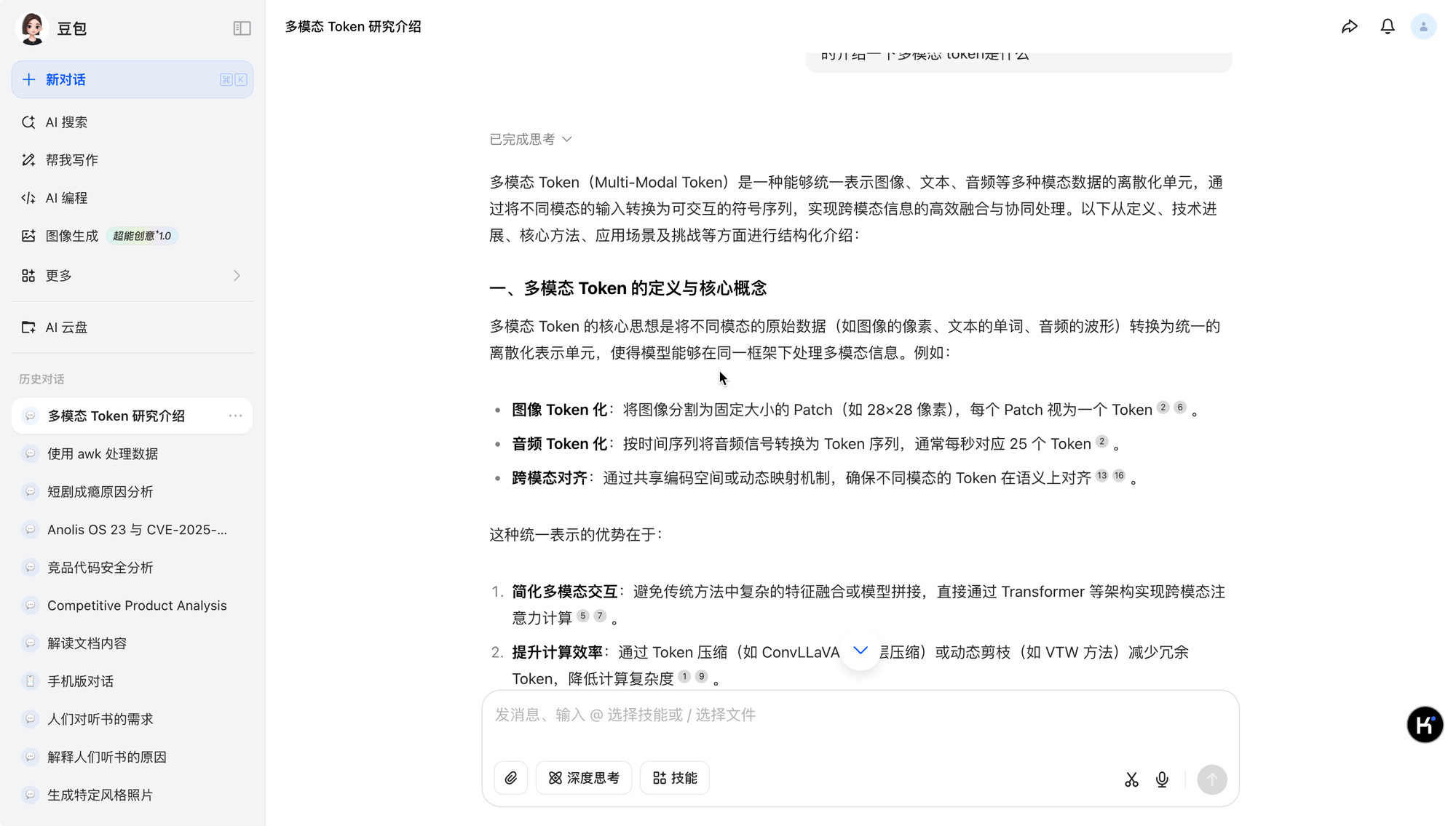
简单对比一下国内几个大模型的 Research 结果方便直观比较:
- 豆包
- Qwen3

个性化研究
Gemini Deep Research给出的报告比较专业,对于非AI算法专业的我来说比较艰深难懂的,为了初步建立该领域的认识,我不需要完全能够读懂专业报告,所以我的做法就是将该报告作为大模型的多模态输入,让大模型帮我整理出适合我的理解的内容,主要的步骤:
- 根据Gemini Deep Research整理的报告,以适合我的方式进行总结和讲解
- 在理解该领域知识的时候,根据自己的需要让大模型整理和回答问题,举两个例子
- 用一个比较通俗易懂的例子说明单一模态的局限性
- 找一下当前常见的大模型是如何处理多模态数据的,是否使用了multi-modal token技术
- 找一下是否已经有统一多模态模型
- OpenAI o3能够通过图片能够定位到图片拍摄的位置,这里的原理是什么,跟multi-modal token的关系是什么
- 重复上一步,直到能够回答自己的疑惑位置
小插曲
在研究过程中,还可以充分借助AI编程工具(Cursor、Cline等)进行小工具和小任务的快速实现。我
在将Gemini Research报告作为附件,进行个性化研究的时候,为了节约token消耗,同时可以让大模型准确的识别报告中引用的资料来源方便查询和校准,我需要对markdown做一下footnote的格式处理,具体来说包括:
- 将reference的number list转换成footnote格式
- 报告原文中的引用数字与footnote对应上
面对这个需求,首先我知道用awk等字符串处理工具肯定可以完成上面的需求,另外我自己并不能熟练地写正则表达式,所以我直接用IDE中的编程Agent帮助解决:
Public discussion